KB 61 (ABAP): Creating a Custom Extractor
Category: Information
Platform: ABAP
Priority: Normal
Version: 2 from 14.11.2021
Description
Please see the information below for development guidelines regarding how to create a custom extractor.
Extractor class definition
Please follow steps below to implement custom extractor.
-
Create a subclass inherited from /BNWVS/CL_EXT_SUPER.
-
Redefine the method PERFORM_METRIC_CALCULATION.
-
Implement custom data extraction logic in the PERFORM_METRIC_CALCULATION method.
The aim is to select metric data into the internal table and store it into the metric cluster for further distribution to Splunk. -
Call STORE_METRIC method and pass extracted data to store data it into the metric cluster.
The call should be made within the redefined PERFORM_METRIC_CALCULATION method.
Extractor class attributes
-
IT_NEXTRUN – UTC timestamp, which contain the next run timestamp (normally should not be used);
-
IT_LASTRUN – UTC timestamp, which contain the last run timestamp (usually used for data extraction as start of the period together with IT_RUNDATETIME).
Extractor methods
-
GET_GROUP_DEF – should be used to retrieve metric group name defined in the Group Definition config (Control Panel->Administrator->Group Definition);
-
PROCESS_APP_SERVER_EXCEPTION – used to store a text of raised exception into the application log. All messages could be viewed from Control Panel;
-
GET_TESTONLYFLAG – used to determine whether it is a test extractor run. In this case some actions may be skipped;
-
GET_TEST_TYPE – used to retrieve the test type, which could be: Display XML or send test data.
-
STORE_METRIC – should be called within PERFORM_METRIC_CALCULATION method to store metric data into the cluster to be sent to Splunk;
-
GET_CONFIG – get/set extractor parameters defined in the Metric Config (Control Panel->Administrator->Setup metric->Metric configuration);
-
PERFORM_METRIC_CALCULATION – is used to extract metric data and store it into the metric cluster;
Important notes
-
Input parameter IT_RUNDATETIME (UTC timestamp) of PERFORM_METRIC_CALCULATION method should be used together with IT_LASTRUN extractor attribute to determine start and end of extraction period.
-
Please use data dictionary table type to store metric data. Please note that currently only standard tables with flat structure are supported (reference fields are not supported). Apart from the dictionary table types it is also possible to use local (defined in the public section of the extractor class) and dynamic types. Dynamic types might impact on performance and memory consumption.
-
Once the data is extracted, the method STORE_METRIC should be called one or more times to store metric data into the metric cluster. Please note that ‘i_subgroup’ is optional parameter and should be used in case two or more dependent data tables should be extracted at the same time (for instance, document header will be stored with empty subgroup and document items will be stored with subgroup ‘ITEM’). Subgroup field will be also sent to Splunk and could be filtered using EVENT_SUBTYPE field.
-
It is possible to redefine an event time by defining ‘TIMESTAMP' field in the dataset. It should contain the time in ABAP timestamp (UTC) format (i.e. types ‘timestamp’ or 'timestampl’). TIMESTAMP field is mapped to _time field on Splunk side. It allows to let Splunk know that event happened some time ago, not at extraction time. For instance it is used in SLG1 extractor to define the time time when message was raised (calculated based on ALDATE and ALTIMEf fields) disregards to extraction time.
-
Reserved fields: UTCDIFF, UTCSIGN, CURRENT_TIMESTAMP, TIMESTAMP, EVENT_TYPE, EVENT_SUBTYPE. Please do not define them as part of the data. Custom fields with same names are replaced with framework ones.
-
Please note, there is no metric size limit as such, since it depends on system configuration and capacity. If stored data is too big to be processed, memory allocation dump will be raised. The recommendation is to split dataset into smaller batches (i.e. per 10000 of events) and call STORE_METRIC several times while entire metric is saved. The maximum recommended is 50000 events at once. Starting from SP 6.07, metric is split automatically by framework inside STORE_METRIC method according to Administrator->Global Config->METRIC_SAVE_BATCH parameter.
Log messages
In order to add own messages into the PowerConnect application log, following methods of /BNWVS/CL_MTR_ENGINE class could be used:
-
ADD_APP_LOG – add custom message;
-
ADD_APP_LOG_WITH_MSG – add message with message class and number;
-
ADD_APP_LOG_WITH_EXC – add message with exception;
Please note that messages will be collected respecting with Application Log Level (Control Panel->Administrator->App Log Level).
Configuration
Once new metric class is created, following config should be made to get it working.
-
Group definition entry (Control Panel->Administrator->Setup Group Def) – should be made to define a group name and run interval. For example, if you set to 3600 seconds (1 hour), when the extractor runs, IT_LASTRUN will be populated with timestamp from 1 hour ago.
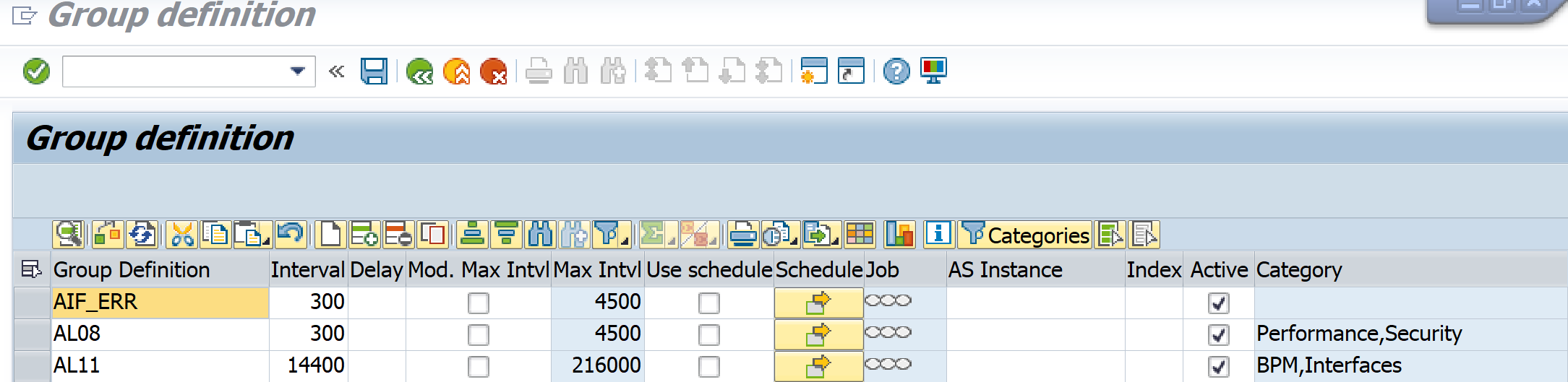
-
Task group entry (Control Panel->Administrator->Setup Task Group) – should be made to define the extractor class and supported system attributes.
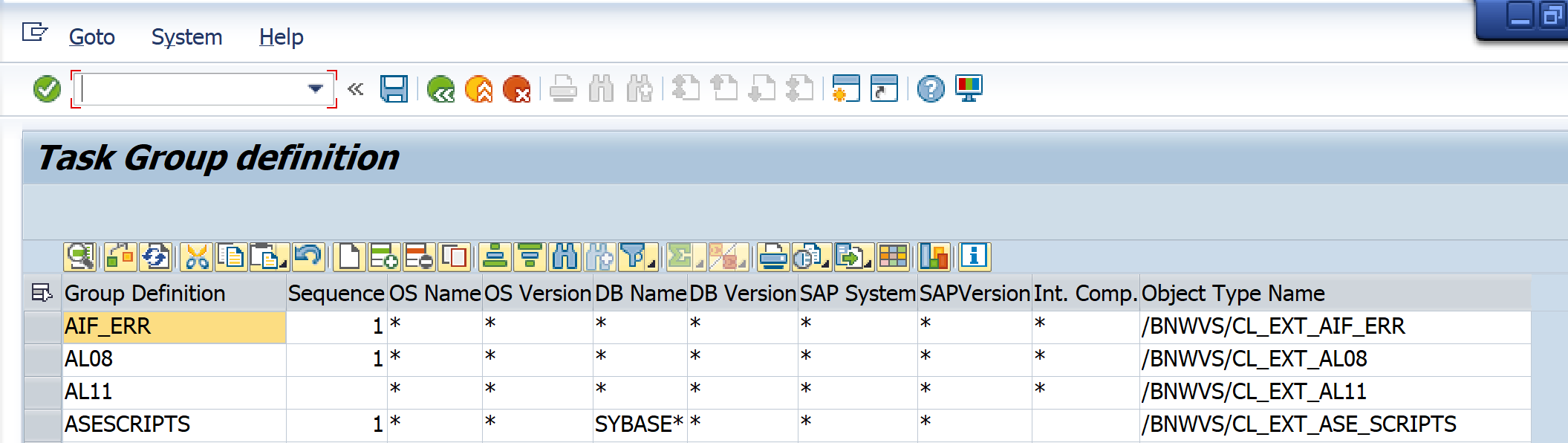
Test extractor
The extractor could be tested using the text tool (Control Panel->Goto->Test Metrics):
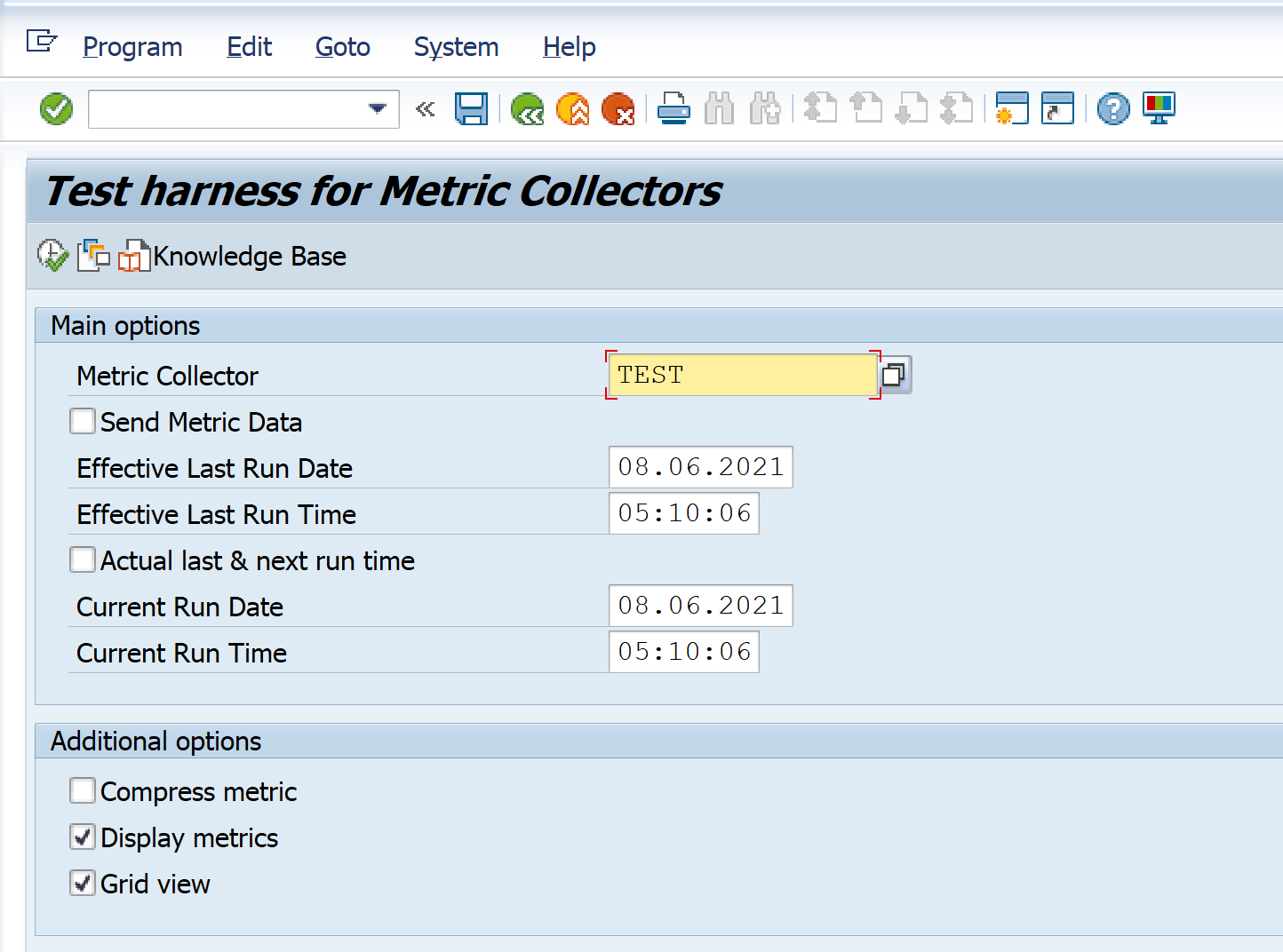
Please note that Send Metric Data checkbox should be set carefully only if test data should be sent to Splunk.
FAQ
-
What value is correct for class attribute C_TABNAME?
-
It is obsolete attribute. It will be removed in next versions, please remove or ignore it.
-
-
How to know if parameter I_SUBGROUP should be filled in method STORE_METRIC? And if we have to fill it, what value is right?
-
The subgroup is used when you need to store some dependent data at the same time. In this case header records are stored with empty I_SUBGROUP and dependent data should be stored with populated I_SUBGROUP parameter. The subgroup itself could have any value (up to you to choose). It will be sent to Splunk as EVENT_SUBTYPE field, which could be used during the search. For instance, subgroup could be used to extract document header and document items. In this case header will not have subgroup, but items could be stored with subgroup ‘ITEM’. Then in Splunk you may distinct headers and items.
-
-
In SAP we’ve created the dictionary objects with the necessary fields but, do we need to export this structure to Splunk platform? Splunk, when it reads the XML file, expects a some type of XML structure but this XML has new fields and structures.
-
No, the framework will take care about the data structure and serialize it accordingly so Splunk will be able to understand and parse it.
-
Product version
|
Product |
From |
To |
|
PowerConnect [NW,S4HANA,S4HANA Cloud] |
* |
* |